When you load data from a SQL Server, instead of individual pipelines, it is best to have one dynamic table controlled process. Learn how to loop through SQL tables dynamically to load from SQL Server to Azure Data Lake. Looping SQL Tables to Data Lake in Azure Data Factory
Setting up the ETL_Control Database
Create the database ETLControl and the table to store the metadata for the ETL runs.
USE [ETLControl]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[ETLControl](
[Id] [int] IDENTITY(1,1) NOT NULL,
[DatabaseName] [varchar](50) NOT NULL,
[SchemaName] [varchar](50) NOT NULL,
[TableName] [varchar](50) NOT NULL,
[LoadType] [varchar](50) NOT NULL
) ON [PRIMARY]
GO
Insert Into [dbo].[ETLControl]
Select 'Databasename', 'dbo', 'TableName1', 'Full'
Insert Into [dbo].[ETLControl]
Select Dataasename', 'dbo', 'TableName2', 'Full'
Setting up Azure Data Factory
- Create a Linked Service to the SQL Database
- Create a DataSet for the ETLControl Database
- Point to the Linked Service for SQL Server
- Do no assign it a table name. This will be done dynamically later.
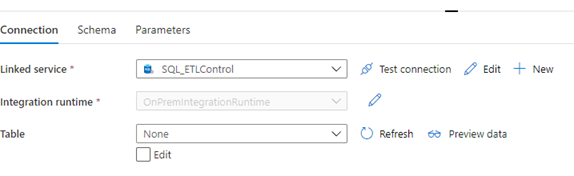
- Add a new Pipeline with the Lookup object
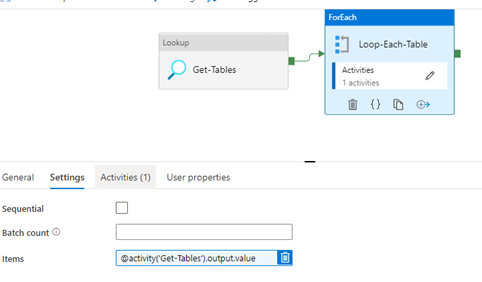
- Set the source Query “Select * From ETLControl”

- Add the For Each Loop
- In the settings add the Dyanmic Item “@activity(‘Get-Tables’).output.value”
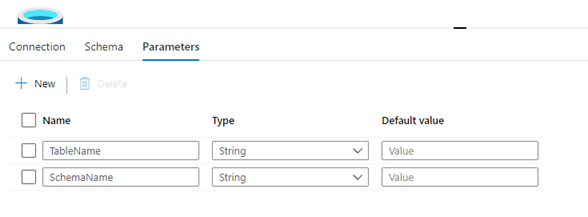
- Add a new data source for the SQL Souce
- Give the SQL a parameter for TableName and SchemaName
- Update the Table to use the variables
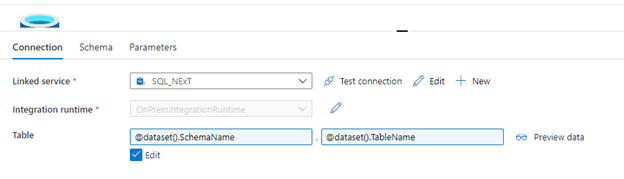
- Add a new data source for the DataLake Destination
- Give the SQL a parameter for FileName
- Update the File Path to the Dynamic content parameter
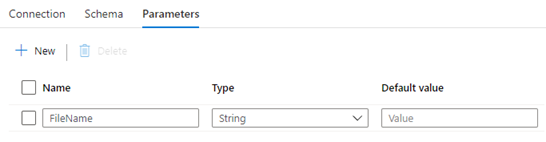

- Add a Copy Activity to the For Each Loop.
- Set the source using the variables from the Lookup
- Set the sink as the file name variable from look up with .csv

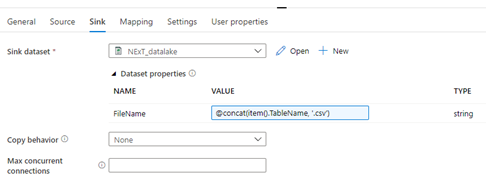
- Debug to run to see new files land in Data Lake with dynamic names. There should be one file for each table that was loaded. You can modify the file names to include folder names and more dynamic storage if needed.

Looping SQL Tables to Data Lake in Azure Data Factory