I wanted to keep this post short since as I mentioned in the previous post about cloud storage, our use case is already an affordable one, but it still makes sense to touch on some of the file movement strategy to other tiers of storage to make sure we are maximizing our cost saving vs. our base level requirements. In S3, you can easily define life cycles rules that allow you to move your files from standard storage, to infrequent and eventually cold storage. The different pricing structures can be found on AWS’s documentation located here.
Let’s quickly discuss the different types of classes offered by AWS. For more details, please see here.
Standard
Amazon S3 Standard offers high durability, availability, and performance object storage for frequently accessed data. Because it delivers low latency and high throughput, S3 Standard is perfect for a wide variety of use cases including cloud applications, dynamic websites, content distribution, mobile and gaming applications, and Big Data analytics.
Infrequent Access
Amazon S3 Standard-Infrequent Access (S3 Standard-IA) is an Amazon S3 storage class for data that is accessed less frequently but requires rapid access when needed. S3 Standard-IA offers the high durability, high throughput, and low latency of S3 Standard, with a low per GB storage price and per GB retrieval fee. This combination of low cost and high performance make S3 Standard-IA ideal for long-term storage, backups, and as a data store for disaster recovery.
Glacier (Cold Storage)
Amazon Glacier is a secure, durable, and extremely low-cost storage service for data archiving. You can reliably store any amount of data at costs that are competitive with or cheaper than on-premises solutions. To keep costs low yet suitable for varying retrieval needs, Amazon Glacier provides three options for access to archives, from a few minutes to several hours.
In our basic scenario where we are getting files representing a whole years’ worth of data, we can consider a scenario where data older then 3 years is moved to infrequent storage while data older then 7 years is moved to cold storage. This way when basic day to day analytics and analysis is occurring, it is against S3 standard, whereas analytics for more directional items such as company direction which occurs less frequently (maybe once a quarter) can occur from the infrequent buckets. If in the rare case an audit is required during an event such as a merger and acquisition, data can then be pulled and provided from cold storage to meet those needs as well. This allows you to maximized cost savings while having an infinite data retention policy.
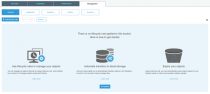
To set up a lifecycle policy on your data, just follow the few simple steps.
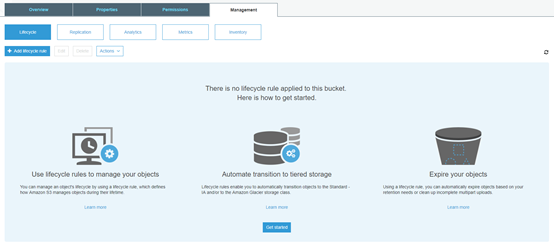
- From your bucket, navigate to Management -> Add Lifecycle Rule
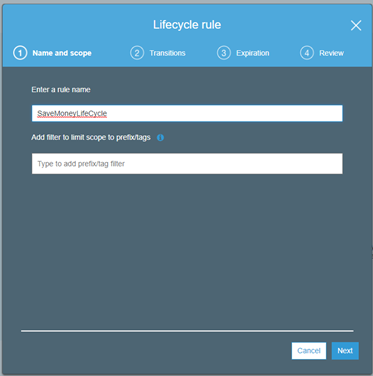
- Give your Rue a name and a scope. You can use tags if needed if you need the policy to apply t a certain set of files.
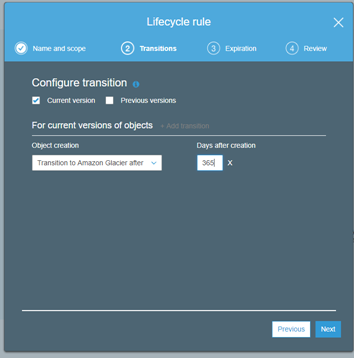
- In the transition and Expiration sections, you can define the time period for when data is moved to another tier and when to expire the file if that is required as well. It is a good idea to tag a file on the upload so that similar tags can be used for the lifecycle rules as well.
- That’s it, you now have an automated policy on your data without an ETL or File task process. You can create as many policies as you need and each can be unique to how you wish to retain your data.