
Modern Data Architecture – Part 5 – Loading Data Lake with Data Factory
The Azure Data Factory (ADF) is a service designed to allow developers to integrate disparate data sources. It is a platform somewhat like SSIS in the cloud to manage the data you have both on-prem and in the cloud.
It provides access to on-premises data in SQL Server and cloud data in Azure Storage (Blob and Tables) and Azure SQL Database. Access to on-premises data is provided through a data management gateway that connects to on-premises SQL Server databases.
It is not a drag-and-drop interface like SSIS. Instead, data processing is enabled initially through Hive, Pig and custom C# activities. Such activities can be used to clean data, mask data fields, and transform data in a wide variety of complex ways.
Creating a Data Factory Resource
- In the search bar, search for “Data Factories”
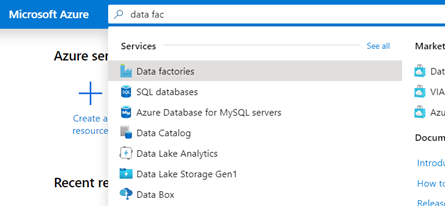
- Select “+ Add” to create a new Data Factory
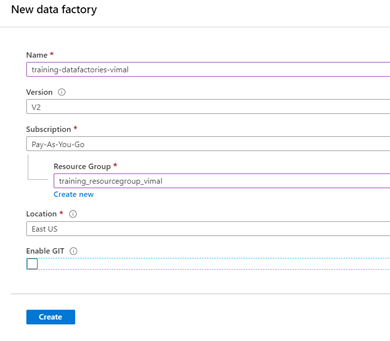
- Fill in the necessary details for your data factory and select “Create”
- Name – “training-datafactories-yourname”
- Name does not allow underscores, use dashes instead
- Version – V2
- Subscription – The default subscription you set up for the demo
- Resource Group “training_resourcegroup_yourname”
- Location – “East US 2” or the same as your resource group
- Enable Git – Uncheck this for the demo. In real development, you will want to link your code to a repository for disaster recovery.
- Name – “training-datafactories-yourname”
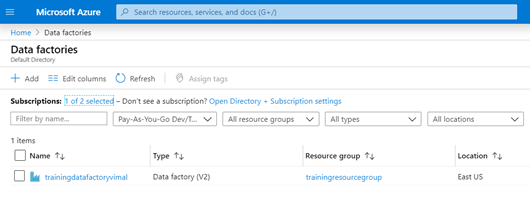
- After a short loading period, your Data Factory resource will be provisioned and listed in your dashboard.
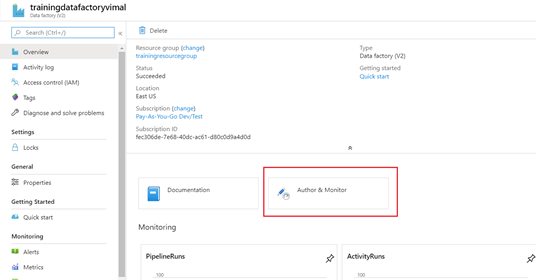
- Click on the new Data Factory Resource to view its details. Select the “Author and Monitor” button to navigate to the editor.
Setting Up a Data Source
- Select “Create a Pipeline” from the editor. In pipelines we can create data flows between data sources and data destinations. For this example, we will be loading data locally stored into our newly provisioned data lake and scheduling the job to run on a schedule. In real world scenarios, the data source could be a FTP file path or a shared drive. We will also create a data source from a SQL database to the data lake as we would in a real world scenario.
- Select Datasets->New dataset.
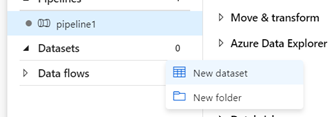
- In the new datasets section, select “SQL Server”

- In Set Properties set the name as “Source_Database” and select a + New Linked Service
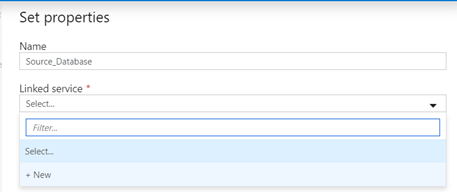
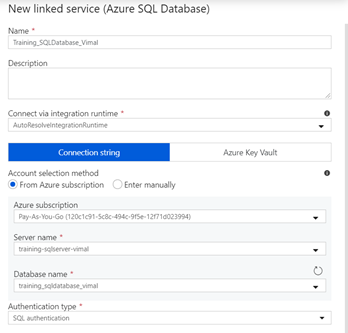
- Complete the remaining details for the SQL Data Connection
- Name “Training_SQLDatabase_yourname”
- Connect via integration run time – Leave as default “AutoResolveIntegationRuntime”
- Connection String
- From Azure Subscription
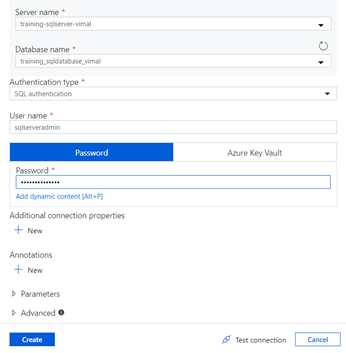
- Server name – “training-sqlserver-yourname”
- Enter all the remaining database credentials from the previous lab and select “Test Connection” to test.
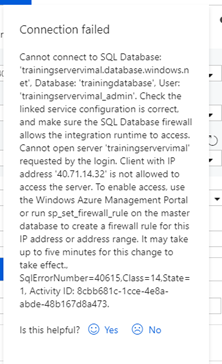
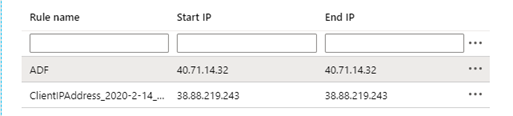
- If you receive a connection error based on IP Firewall, record the IP address and whitelist it on the database similar to how it was done in lab 4.
- In the last properties window, set the Table Name to “sales.customers”.

- Click “OK” to save.
- Create a new connection, but this time select “Azure Blog Storage”
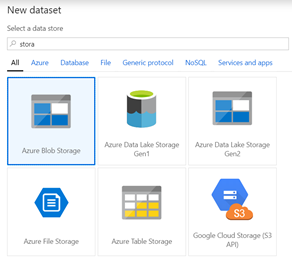
- Select Comma Delimeted and name set it as “Destination_CSV” and select a + New Linked Service
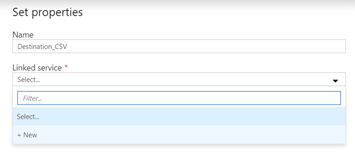
- In the New linked servers window enter the necessary details
- Name – “training_storage_yourname”
- Connect via integration run time – Leave as default “AutoResolveIntegationRuntime”
- Authentication method – Account Key
- Account selection method – From Azure Subscription
- Select the training storage you created in earlier labs
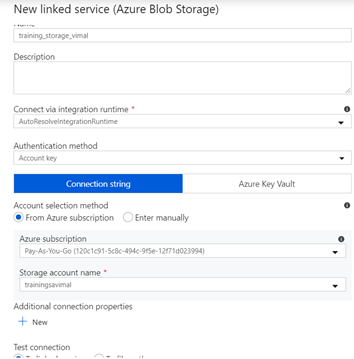
- Once complete, select test connection and create.
- On the set properties, set a file path called “root/raw”
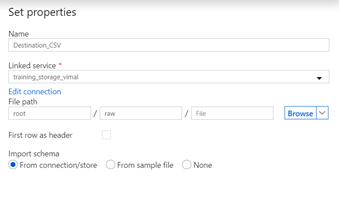
- Set “First Row as Header” and Ok to save.
- Navigate to the connections tab in the details and select “Test Connection” to test.
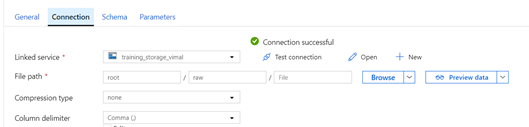
Create a Data Transfer
- From the Pipeline tab, In the “Move and Transform” section in the Activities, drag and drop a “Copy Data” task to the main window. In the properties editor below, select “Source” and select “Source_Database”
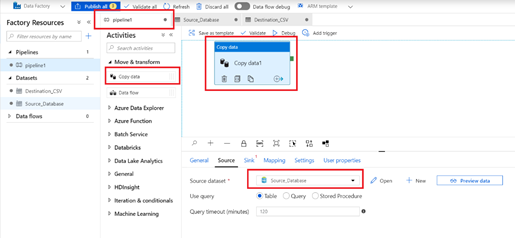
- Select “Query” and write the following query. Use the Preview Data to validate the query works as expected.
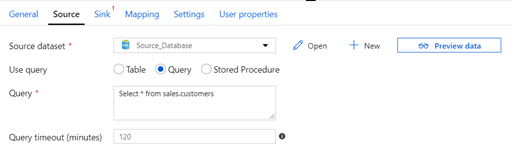
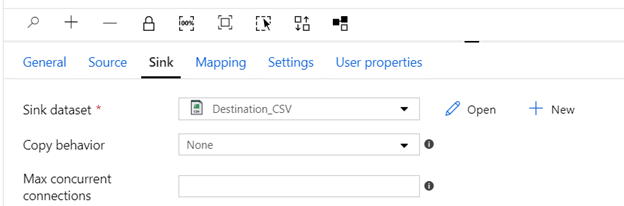
- Click on “Sink” and select “Destination_CSV”
Publishing and Running
- Select publish at the top of the window.
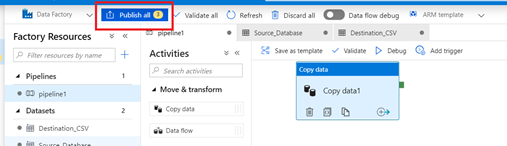
- Select “debug” to run the job.
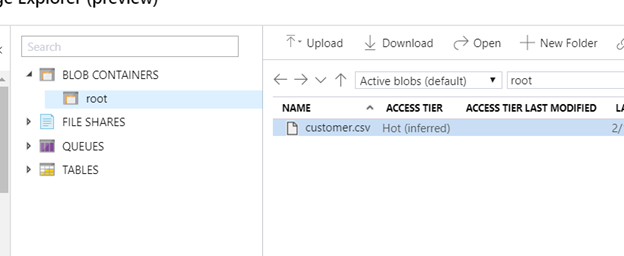
- Once the job has succeeded, navigate back to your Storage account and view the storage browser. The new file “customer.csv” should now be available.
Setting up the job to run automatically
- Back in Azure Data Factory, select “Add Trigger->New Edit” from your Pipeline
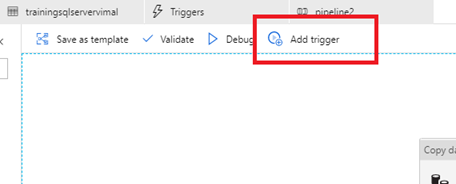
- Create a new trigger
- Type – Schedule
- Start Date – Todays Date
- Reoccurrence – Every 1 Month (We don’t need this to run as frequently yet)
- End No End
- Select “OK to save and “Publish” to push your changes.
- From the triggers menu at the bottom, you can now see your new trigger and activate and deactivate it manually.
Be sure to check out my full online class on the topic. A hands on walk through of a Modern Data Architecture using Microsoft Azure. For beginners and experienced business intelligence experts alike, learn the basic of navigating the Azure Portal to building an end to end solution of a modern data warehouse using popular technologies such as SQL Database, Data Lake, Data Factory, Data Bricks, Azure Synapse Data Warehouse and Power BI. Link to the class can be found here or directly here.
Part 1 – Navigating the Azure Portal
Part 2 – Resource Groups and Subscriptions
Part 3 – Creating Data Lake Storage
Part 4 – Setting up an Azure SQL Server
Part 5 – Loading Data Lake with Azure Data Factory
Part 6 – Configuring and Setting up Data Bricks
Part 7 – Staging data into Data Lake
Part 8 = Provisioning a Synapse SQL Data Warehouse
Part 9 – Loading Data into Azure Data Synapse Data Warehouse
Modern Data Architecture – Part 5 – Loading Data Lake with Data Factory