Modern Data Architecture – Part 7 – Staging Data into Data Lake
In Lab 5, we demonstrated loaded data from our sample SQL server into our data lake. Although this tool is very handy, it creates a new service and set of tools that need to be provisioned and monitored. It is best to use ADF more as an workflow orchestration tool and use a single tool to handle all of your ETL. Data Brinks provides a robust tool to handle this task. We will investigate how to query data from your SQL Server and load your data lake.
For this lab we will be hard coding the access keys and credentials directly into the code. The optional section at the bottom will demonstrate how to configure Azure credentials secret keys to configure this the correct way as you would in production.
Connect and Query SQL Server
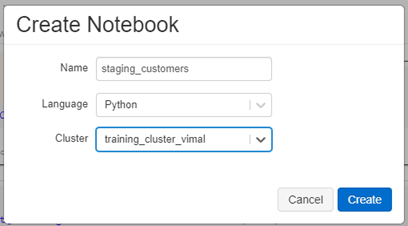
- Create a new workbook in your Data Bricks and name it “staging_customers”
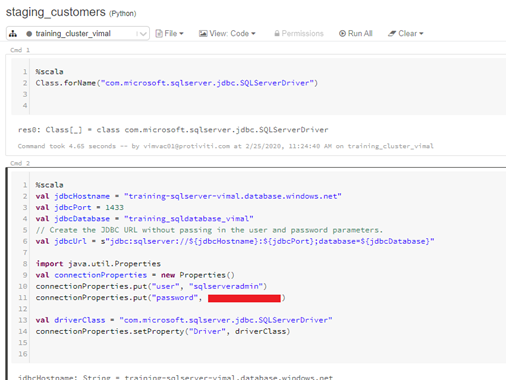
Copy the Query below and paste it into your Data Bricks Window. Replace the highlighted sections with your database information. Most of our code will be writing using Scala to start. We will place each piece of code into its own cells to make the job a bit easer to read and test. Copy and paste the following code into your notebook. We will be using hard coded credentials and keys for the lab but in real world, be sure to configure secret key access only.
Example
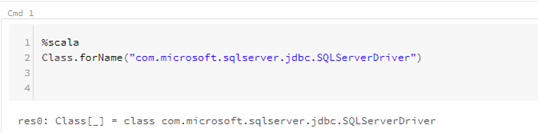
Block 1
Description – This sets the initial driver for our database connection
Code
%scala
Class.forName(“com.microsoft.sqlserver.jdbc.SQLServerDriver”)
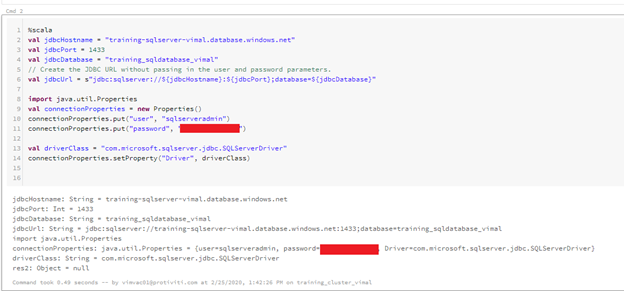
Block 2
Description – We configure and test the connection. Replace the items highlighted below with you SQL Server name, database name, username and password respectively.
Code
%scala
val jdbcHostname = “training-sqlserver-vimal.database.windows.net”
val jdbcPort = 1433
val jdbcDatabase = “training_sqldatabase_vimal”
// Create the JDBC URL without passing in the user and password parameters.
val jdbcUrl = s”jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase}”
import java.util.Properties
val connectionProperties = new Properties()
connectionProperties.put(“user”, “sqlserveradmin”)
connectionProperties.put(“password”, “Password123”)
val driverClass = “com.microsoft.sqlserver.jdbc.SQLServerDriver”
connectionProperties.setProperty(“Driver”, driverClass)
Block 4
Description – This allows us to review and test the connection to our sales.customers table in the database
Code
%scala
val customer = spark.read.jdbc(jdbcUrl, “sales.customers”, connectionProperties)
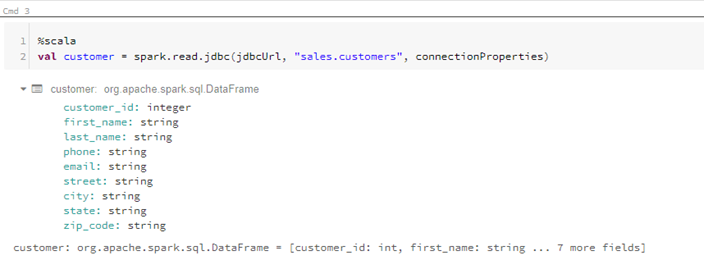
Block 5
Description – Select the data from the table for display
Code
%scala
customer.select(“*”).show()
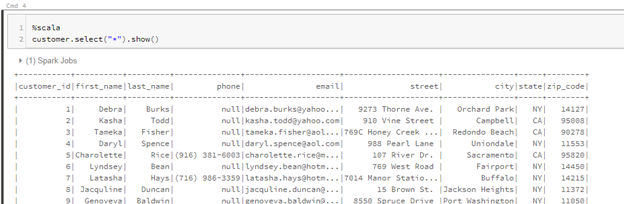
Block 6
Description – This section connects your data bricks storage to your data lake so that we can push data to the data lake in the next step. Insert your blob name, your storage account name, the destionation folder, the destination folder, the storage account name and your access key respectively.
Code
%scala
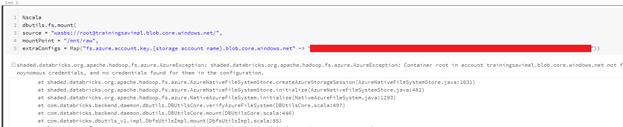
dbutils.fs.mount(
source = “wasbs://root@trainingsavimal.blob.core.windows.net/raw”,
mountPoint = “/mnt/raw”,
extraConfigs = Map(“fs.azure.account.key.trainingsavimal.blob.core.windows.net” -> “ youraccesskey “))
To access “youraccesskey”, we are going to need some additional information. From the azure portal, navigate back to your Storage Account “trainingsayourname” and select “Access Keys”
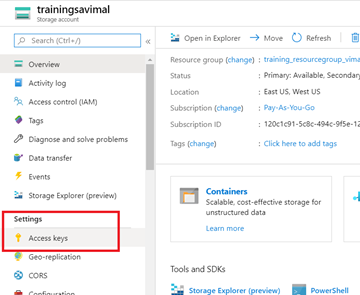
Block 7
Description – This last section pushed your data to a csv on to the data lake. Upon completion, you can now see you new data file on your storage via the storage explorer. There will also be a folder containing some of the data tranfer metadata.
Code
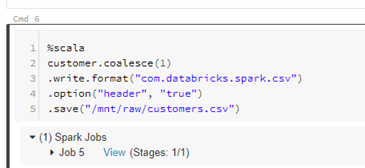
%scala
customer.coalesce(1)
.write.format(“com.databricks.spark.csv”)
.option(“header”, “true”)
.save(“/mnt/raw/customers.csv”)
Be sure to check out my full online class on the topic. A hands on walk through of a Modern Data Architecture using Microsoft Azure. For beginners and experienced business intelligence experts alike, learn the basic of navigating the Azure Portal to building an end to end solution of a modern data warehouse using popular technologies such as SQL Database, Data Lake, Data Factory, Data Bricks, Azure Synapse Data Warehouse and Power BI. Link to the class can be found here or directly here.
Part 1 – Navigating the Azure Portal
Part 2 – Resource Groups and Subscriptions
Part 3 – Creating Data Lake Storage
Part 4 – Setting up an Azure SQL Server
Part 5 – Loading Data Lake with Azure Data Factory
Part 6 – Configuring and Setting up Data Bricks
Part 7 – Staging data into Data Lake
Part 8 = Provisioning a Synapse SQL Data Warehouse
Part 9 – Loading Data into Azure Data Synapse Data Warehouse
Modern Data Architecture – Part 7 – Staging Data into Data Lake