
Modern Data Architecture – Part 9 – Loading Data into Synapse Data Warehouse
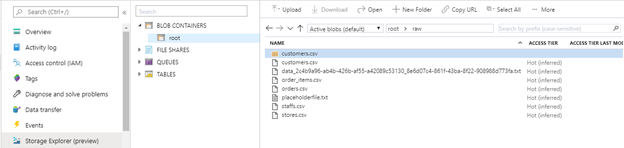
Now that we have provisioned a Synapses Data Analytics environment, we are now ready to begin loading data into this environment. In lab 7, we loaded a single table “sales.customer” to our data lake. To complete this lab, you will either need to complete the same exercise for the tables listed below. To make it easier, we have included the csv files you can upload directly to the data lake raw folder as well in the Datafiles folder included with this lab.
Tables
Sales.customers
Sales.order_items
Sales.orders
Sales.staffs
Sales.stores
- Open or navigate back to your Data Bricks environment
- We will be creating a similar script as we did in lab 7 but in reverse. We will connect to the data lake first and then load this data to our data warehouse.
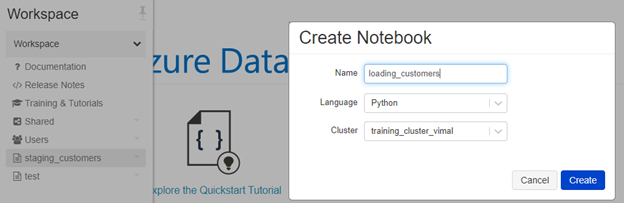
- Create a new work book called “loading_customers”
Block 1
Description – This section connects your data bricks storage to your data lake so that we can pull data from the data lake in the next step. This is the quick and easy way to accomplish this but your access keys are visible and shared in your code and not best practice. For production, be sure to use secret access keys.
Insert your storage account name, the destination folder and your access key respectively.
Code
%scala
spark.conf.set(“fs.azure.account.key.trainingsavimal.dfs.core.windows.net”,”youraccesskey“)
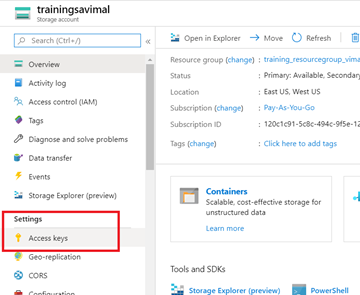
To access “youraccesskey”, we are going to need some additional information. From the azure portal, navigate back to your Storage Account “trainingsayourname” and select “Access Keys”

Block 2
Description – This will store your data to a data frame in data bricks memory.
Code
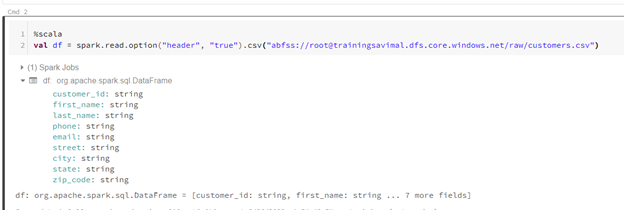
%scala
val df = spark.read.option(“header”, “true”).csv(“abfss://root@trainingsavimal.dfs.core.windows.net/raw/customers.csv”)
Block 3
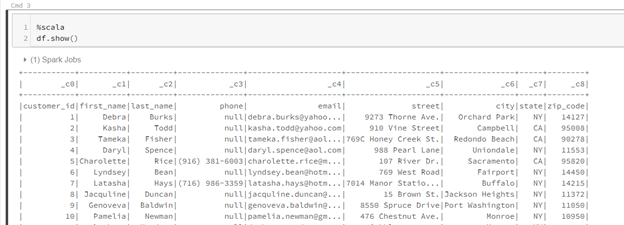
Description – This will display the contents of what has now been stored into the dataframe. Code to manipulte or transform the data can now be done if needed.
Code
%scala
df.show()
Block 3
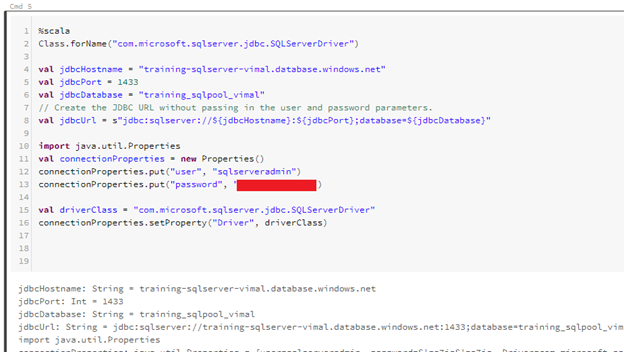
Description – Similar to before, we now connect to our SQL Server instance but this time we connect to our Synapses database instead of our SQL Server Database.
Code
%scala
Class.forName(“com.microsoft.sqlserver.jdbc.SQLServerDriver”)
val jdbcHostname = “training-sqlserver-vimal.database.windows.net”
val jdbcPort = 1433
val jdbcDatabase = “training_sqlpool_vimal”
// Create the JDBC URL without passing in the user and password parameters.
val jdbcUrl = s”jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase}”
import java.util.Properties
val connectionProperties = new Properties()
connectionProperties.put(“user”, “sqlserveradmin”)
connectionProperties.put(“password”, “Password1234”)
val driverClass = “com.microsoft.sqlserver.jdbc.SQLServerDriver”
connectionProperties.setProperty(“Driver”, driverClass)
Block 4
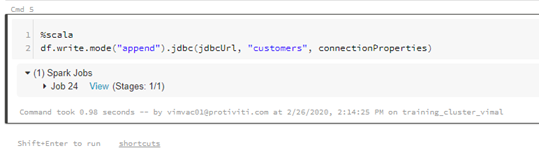
Description – We can now write the contents of our data frame to our SQL Server Synapses database
Code
%scala
df.write.mode(“append”).jdbc(jdbcUrl, “customers”, connectionProperties)
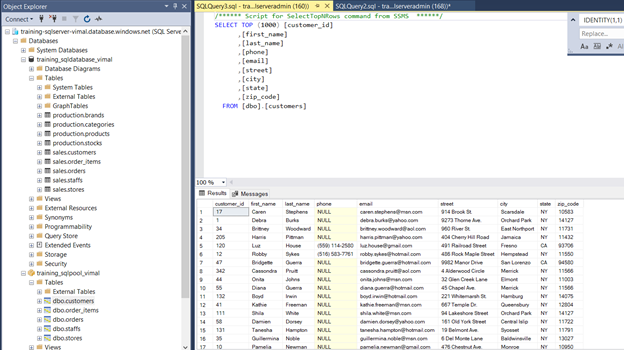
- Heading back to your SQL Server Management Studio and query the table customers. You should now see data available in this table
Be sure to check out my full online class on the topic. A hands on walk through of a Modern Data Architecture using Microsoft Azure. For beginners and experienced business intelligence experts alike, learn the basic of navigating the Azure Portal to building an end to end solution of a modern data warehouse using popular technologies such as SQL Database, Data Lake, Data Factory, Data Bricks, Azure Synapse Data Warehouse and Power BI. Link to the class can be found here or directly here.
Part 1 – Navigating the Azure Portal
Part 2 – Resource Groups and Subscriptions
Part 3 – Creating Data Lake Storage
Part 4 – Setting up an Azure SQL Server
Part 5 – Loading Data Lake with Azure Data Factory
Part 6 – Configuring and Setting up Data Bricks
Part 7 – Staging data into Data Lake
Part 8 = Provisioning a Synapse SQL Data Warehouse
Part 9 – Loading Data into Azure Data Synapse Data Warehouse
Modern Data Architecture – Part 9 – Loading Data into Synapse Data Warehouse