Category: Big Data
-

Provisioning an Azure Event Hub to capture real time streaming data
Provisioning an Azure Event Hub to capture real time streaming data is fairy easy once you have an Azure account. Event Hubs can be used to capture data from many different sources including databases or IoT devices. As we look at building a CDC streaming ETL, let’s take a look at the basics of Event…
-

Visual Studio Dev Essentials to download and install SQL Server Developer Edition
With the Microsoft BizSpark program now gone, so is the easy way to download and install SQL Server to your local machine for development purposes. Let’s take a look at using Visual Studio Dev Essentials to download and install SQL Server Developer Edition on your local machine for data development.
-
Streaming ETL using CDC and Azure Event Hub. A Modern Data Architecture.
In Modern Data architecture, As Data Warehouses have gotten bigger and faster, and as big data technology has allowed us to store vast amounts of data it is still strange to me that most data warehouse refresh processes found in the wild are still some form of batch processing. Even Hive queries against massive Hadoop…
-
The Modern Data Warehouse; Azure Data Lake and U-SQL to combine data
The modern data warehouse will need to use Azure Data Lake and U-SQL to combine data. Begin by navigating to your Azure Portal and searching for the Data Lake Analytics Resource. Let’s start by creating a new Data Lake. Don’t worry, this service only charges on data in and out, not just remaining on like…
-
The Modern Data Warehouse; Running Hive Queries in Visual Studio to combine data
In previous posts we have looked at storing data files to blob storage and using PowerShell to spin up an HDInsight Hadoop cluster. We have also installed some basic software that will help us get going once the services are provisioned. Now that the basics are ready, it is time to process some of that…
-
Setting up tools to work with HDInsights and run Hive Queries – Azure Data Lake Tools and Azure Storage Browser
Two tools that are going to make life a bit simpler if you are going to be working with HDInsights and Azure blog storage are “Azure Data Lake and Stream Analytic Tools for Visual Studio” and Azure Storage Browser. Azure Data Lake and Stream Analytic Tools for Visual Studio To run Hive Queries, you’re going…
-
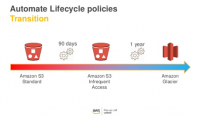
Big Data for The Rest of Us. Affordable and Modern Business Intelligence Architecture – Adding Lifecycles to your S3 buckets to save cost and retain data forever!
I wanted to keep this post short since as I mentioned in the previous post about cloud storage, our use case is already an affordable one, but it still makes sense to touch on some of the file movement strategy to other tiers of storage to make sure we are maximizing our cost saving vs.…
-
Big Data for The Rest of Us. Affordable and Modern Business Intelligence Architecture – Auto uploading and syncing your data using AWS S3
The first process in any data warehouse project is obtaining the data into a staging environment. In the traditional data warehouse, this required an ETL process to pick up data files from a local folder or FTP, and in some cases, a direct SQL connection to source systems to then load into a dedicated staging…
-
Big Data for The Rest of Us. Affordable and Modern Business Intelligence Architecture – An Introduction using AWS
If you google the use cases for Big Data, you will usually find references to scenarios such as web click analytics, streaming data or even IOT sensor data, but most organizations data needs and data sources never fall into any of these categories. However, that does not mean they are not great candidates for a…
-
The Modern Data warehouse; The low-cost solution using Big Data with HDInsight and PowerShell
Organizations have been reluctant to transition their current business intelligence solutions from the traditional data warehouse infrastructure to big data for many reasons, but there are two reasons that are false barrier to entries, cost and complexity of provisioning environments. In the post below, we will cover how to use PowerShell to commission and decommission…