In previous posts we have looked at storing data files to blob storage and using PowerShell to spin up an HDInsight Hadoop cluster. We have also installed some basic software that will help us get going once the services are provisioned. Now that the basics are ready, it is time to process some of that data using Hive and Visual Studio. In this scenario, we will be loading our Happiness Index data files into Hive tables and then consolidating that data into a single file.
Data Warehouse
Setting up tools to work with HDInsights and run Hive Queries – Azure Data Lake Tools and Azure Storage Browser

Two tools that are going to make life a bit simpler if you are going to be working with HDInsights and Azure blog storage are “Azure Data Lake and Stream Analytic Tools for Visual Studio” and Azure Storage Browser.
Azure Data Lake and Stream Analytic Tools for Visual Studio
- To run Hive Queries, you’re going to need to install Azure Data Lake and Stream Analytic Tools to your version of Visual Studio, sometimes referred to as HDInsight tools for Visual Studio or Azure Data Lake tools for Visual Studio. You can install directly from Visual studio by selection Tools -> Get Tools and Features.
Big Data for The Rest of Us. Affordable and Modern Business Intelligence Architecture – Adding Lifecycles to your S3 buckets to save cost and retain data forever!
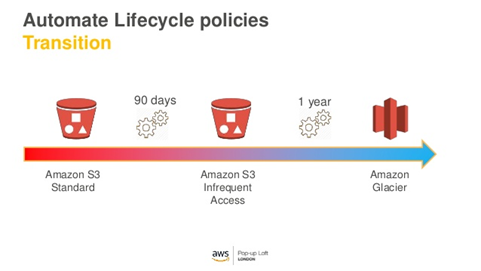
I wanted to keep this post short since as I mentioned in the previous post about cloud storage, our use case is already an affordable one, but it still makes sense to touch on some of the file movement strategy to other tiers of storage to make sure we are maximizing our cost saving vs. our base level requirements. In S3, you can easily define life cycles rules that allow you to move your files from standard storage, to infrequent and eventually cold storage. The different pricing structures can be found on AWS’s documentation located here.
Big Data for The Rest of Us. Affordable and Modern Business Intelligence Architecture – Auto uploading and syncing your data using AWS S3
The first process in any data warehouse project is obtaining the data into a staging environment. In the traditional data warehouse, this required an ETL process to pick up data files from a local folder or FTP, and in some cases, a direct SQL connection to source systems to then load into a dedicated staging database. In the new process we will be defining we will be using an S3 bucket to be our new staging environment. Staging data will forever live in raw file data, as any analysis or query needed against this data will be handled via tools like Athena or Elastic Map Reduce which we will cover later. Keeping this data in S3 (known as Azure Blog storage in the Microsoft world) is a cheap and convenient way to store massive amounts of data for a relatively low cost. For example, the first 50 TB is stored at a cost of $0.023 per GB. In most use cases we can assume our data requirements stay under this threshold so if we are assuming 1 TB of data files, we can ball park around $23 a month for storage or $276 a year. Pretty cheap.
Big Data for The Rest of Us. Affordable and Modern Business Intelligence Architecture – An Introduction using AWS
If you google the use cases for Big Data, you will usually find references to scenarios such as web click analytics, streaming data or even IOT sensor data, but most organizations data needs and data sources never fall into any of these categories. However, that does not mean they are not great candidates for a Modern Big Data BI solution.
The Modern Data warehouse; The low-cost solution using Big Data with HDInsight and PowerShell
Organizations have been reluctant to transition their current business intelligence solutions from the traditional data warehouse infrastructure to big data for many reasons, but there are two reasons that are false barrier to entries, cost and complexity of provisioning environments. In the post below, we will cover how to use PowerShell to commission and decommission HDInsight clusters on Azure. If used correctly, this allows organizations to cut cost down to the sub $100 dollars a month for a big data solution by creating the clusters on demand on weekends or evenings, processing all the heavy big data they may have, creating the data files required and then deleting the cluster so no charges are incurred the rest of the time. The Storage files can remain, so when you spin up the cluster again, it is if nothing ever happened to your previous data or work. The scrips below will remove the storage files as well and will need to be modified to keep that portion around. You can also move your storage to a different resource group to avoid it being removed.
Accelerating the Staging Process for your Data Warehouse

Real Estate Data Warehouse – Accelerating the Staging Process
The script below can be used to build a staging environment for any sort of industry and not just real estate related databases. The specifics of a RE Data warehouse will be covered in future blog post. It will allow you to Accelerating the Staging Process for your Data Warehouse
Getting Data from Yardi Log Shipping Part 2

Until recently obtaining data externally from Yardi was reserved to two methods. The first was via a nightly backup of the database or if you were paying for private cloud, then the second was via direct SQL query access over VPN. Both worked very well but both also had some minor flaws. We also have … Read more