
In previous posts we have looked at storing data files to blob storage and using PowerShell to spin up an HDInsight Hadoop cluster. We have also installed some basic software that will help us get going once the services are provisioned. Now that the basics are ready, it is time to process some of that data using Hive and Visual Studio. In this scenario, we will be loading our Happiness Index data files into Hive tables and then consolidating that data into a single file.
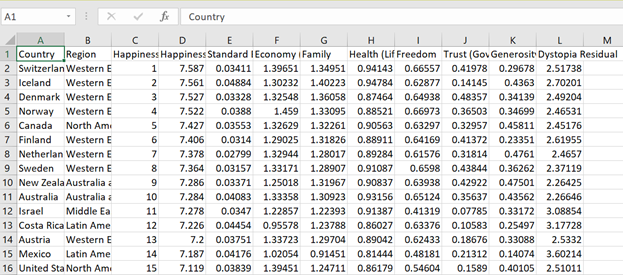
For this tutorial we are going to leverage Azure Storage Browser to view our storage files as well as create folders. You can use this tool as well as the shell to create new folders and upload your data files. The actual folder will not be created until you upload files using this tool. In a real-world scenario, you would use a file transfer task or data factory to stage your files.
Open the tool and sign into your Azure account. Once created, navigate to your HDInsights Cluster and in your storage and create a new folder in your Hive Storage called “data” and uploaded all 3 of our files to this location.
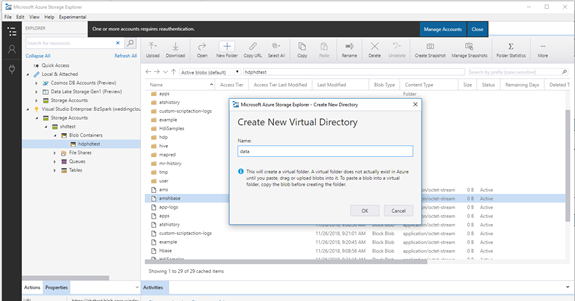
Open Visual Studio with your newly installed “Azure Data Lake Tools” installed. If you look at your server explorer and ensure you are signed in with the same Azure account as where your cluster is located, you will see the cluster listed in the menu.
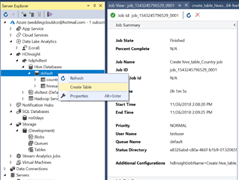
You can create a new table directly from the server explorer. In the tool you can either script or use the wizard to create the new table. Create it so that it has the same column names as the file. For the example below we will just run the create table and the load table step as one Hive script. Update the script to load the 2016 and the 2017 files as well.
CREATE TABLE IF NOT EXISTS default.sourcedata2015(Country string,
Region string,
HappinessRank float,
HappinessScore float,
LowerConfidenceInterval float,
UpperConfidenceInterval float,
Economy_GDPperCapita float,
Family float,
Health_LifeExpectancy float,
FreedomTrust_GovernmentCorruption float,
GenerosityDystopiaResidual float)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘,’
COLLECTION ITEMS TERMINATED BY ‘\002’
MAP KEYS TERMINATED BY ‘\003’
STORED AS TEXTFILE;
LOAD DATA INPATH ‘/data/2015.csv’ INTO table sourcedata2015;
Once you have created your 3 new Hive tables, it is time to consolidate them into one table using a simple SQL like union statement and adding the year column to the end.
Select * from
(
SELECT *, ‘2015’ as Year FROM sourcedata2017 b
UNION ALL
SELECT *, ‘2016’ as Year FROM sourcedata2017 c
UNION ALL
SELECT *, ‘2017’ as Year FROM sourcedata2017 d
) CombinedTable
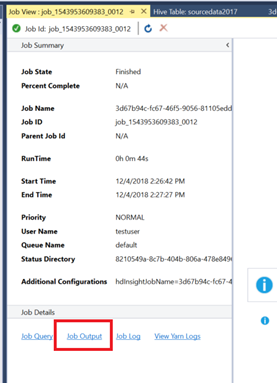
Once the job is complete, you should be able to view the results in see by clicking “Job Output”. All we have done here is created a select statement, but this data could have also been inserted into a new Hive table for either more processing or a push to a targeted data warehouse.
I hope this introduction helps you get off the ground in the basics of running Hive queries. In later posts we will look at how HDinsights intersects with Azure Data Lake and Data Factory. Before you leave, be sure to delete your HDCluster. Since this services runs as an hourly service and is not billed on a job basis, so it will continue to charge your account. You can either delete via the Azure dashboard or using the PowerShell script from our previous posts.