
In Modern Data architecture, As Data Warehouses have gotten bigger and faster, and as big data technology has allowed us to store vast amounts of data it is still strange to me that most data warehouse refresh processes found in the wild are still some form of batch processing. Even Hive queries against massive Hadoop infrastructures are essentially fast performing bath queries. Sure, they may occur every half day or even every hour but the speed of business continues to accelerate and we must start looking at architecture that combines the speed and transactional processing of Kafka/Spark/Event Hubs into creating a real time streaming ETL to load a data warehouse at a cost that is comparable and even cheaper then purchasing an ETL tool. Let’s look at Streaming ETL using CDC and Azure Event Hub.
Interested in Learning More about Modern Data Architecture? .
Side Note: Want to learn SQL or Python for free. In less then 10 minutes a day and less than an hour total? Signup for my free classes delivered daily right to your email inbox for free!


Now back to the article…
For this series, we will be looking at Azure Event Hubs or IoT Hubs. These were designed to capture fast streaming data of millions of rows from IoT devices or streaming data like Twitter. But why should this tool be limited to these use cases? Most businesses have no need or requirement for this use case, but we can use this technology to create a live streaming ETL to your data warehouse or your reporting environment with out sacrifice performance or creating a strain on your source systems. This architecture can be used to perform data synchronization between systems and other integrations as well, and since we are not using it to its full potential of capturing millions of flowing records, our costs end up being pennies a day!
Others have emulated this sort of process by using triggers on their source table, but this can potentially add an extra step of processing and overhead to your database. By enabling change data capture natively on SQL Server, it can be much lighter than a trigger. You can then take the first steps to creating a streaming ETL for your data. If CDC is not available, simple staging scripts can be written to emulate the same but be sure to keep an eye on performance. Let’s take a look at the first step of setting up native Change Data Capture on your SQL Server tables
Steps
- First, enable Change Data Capture at the Database and Table Level using the following scripts. More information is available on the Microsoft Site. If you are not using SQL Server or a tool that has organic CDC build it, a similar process can be hand built a read only view by leveraging timestamps on last created date and last updated date.
sys.sp_cdc_enable_db
EXECUTE sys.sp_cdc_enable_table
@source_schema = N’dbo’
, @source_name = N’Task’
, @role_name = N’cdc_Admin’;
GO
This step will enable CDC on the database as well as add it to the table “Task”. SQL Agent must be running as two jobs are created during this process, one to load the table and one to clean it out.
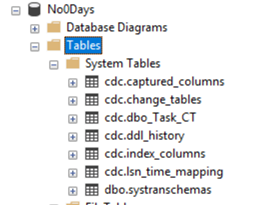
Once the CDC is enabled, SQL Server will automatically create the following tables “schema_tablename_CT” in the System folder section. This table will now automatically track all data changes that occur on that table. You can reference the _$operationcode to determine what change occurred with the legend below. If you wish to capture changes to only certain fields, see the Microsoft documentation on CDC to see how that can be set. If you are hand writing your SQL, this can also be programmed in when building your staging query.
1 = delete
2 = insert
3 = update (captured column values are those before the update operation). This value applies only when the row filter option ‘all update old’ is specified.
4 = update (captured column values are those after the update operation)

Now once you add, edit or delete a record, you should be able to find it in the new CDC table. Next, we will look at scanning this table and turning the data to JSON to send to an Event Hub!
For more information on SQL CDC please see their documentation here.
Be sure to check out my full online class on the topic. A hands on walk through of a Modern Data Architecture using Microsoft Azure. For beginners and experienced business intelligence experts alike, learn the basic of navigating the Azure Portal to building an end to end solution of a modern data warehouse using popular technologies such as SQL Database, Data Lake, Data Factory, Data Bricks, Azure Synapse Data Warehouse and Power BI. Link to the class can be found here.
Part 1 – Navigating the Azure Portal
Part 2 – Resource Groups and Subscriptions
Part 3 – Creating Data Lake Storage
Part 4 – Setting up an Azure SQL Server
Part 5 – Loading Data Lake with Azure Data Factory
Part 6 – Configuring and Setting up Data Bricks
Part 7 – Staging data into Data Lake
Part 8 = Provisioning a Synapse SQL Data Warehouse
Part 9 – Loading Data into Azure Data Synapse Data Warehouse