
Modern Data Architecture – Part 6 – Configuring and setting up Data Bricks
Azure Databricks is an Apache Spark-based analytics platform optimized for the Microsoft Azure cloud services platform. Databricks is an industry-leading, cloud-based data engineering tool used for processing and transforming massive quantities of data and exploring the data through machine learning models
Azure Data Bricks provides a highly flexible data framework allowing for developers to build an entire ETL framework using Python and SQL. We will explore how to stage data from your SQL Server to your Data Lake in this Lab.
Creating a Data Bricks Resource
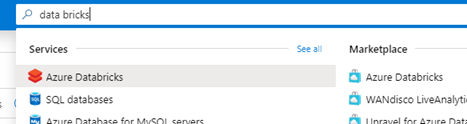
- In the search bar, search for “Data Bricks” and select “+ Add”
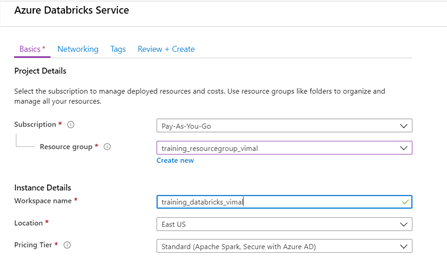
- Subscription – Your training subscription
- Resource Group – “training_resourcegroup_yourname”
- Workspace Name – “training_databricks_yourname”
- Location – East US 2
- Pricing Tier – Standard
- Pricing will only offer when the Data Bricks is in use. No charges will be incurred if you do not have a cluster running.
- Select “Review and Create to complete”
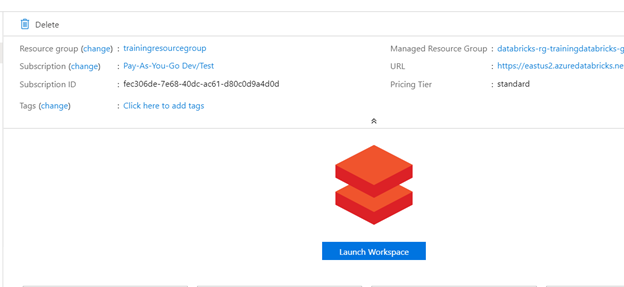
- Once completed you will be able to launch the data bricks application.
- This service runs its own portal and toolset and is interfaced with Azure via single sing on authentication. Select “Launch Workspace” to launch the tool.
Navigating Data Bricks
- Review the menu on the left-hand side
- The two main sections we will be working with will be Workspace and Clusters. All data bricks code can only run on an active cluster so we will create one first.
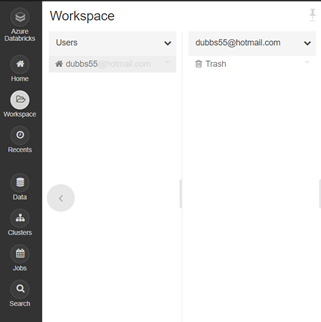
- Select “Clusters-Create Cluster”
- Enter the details for the cluster
- Cluster Name – training_cluster_yourname”
- Cluster Mode – Standard
- Pool – None
- Data Bricks Run time – Scala 2.11, Spark 2.4.4)
- Auto Pilot Options (Very Important, this will shut down your clusters when not in use to ensure cost is minimized)
- Disable – Enable Autoscaling
- Enable – Terminate after 15 minutes of Inactivity
- Worker Type – Standard DS2
- Workers – 1 (Since our lab is a low volume and frequency request, do no not need a lot of horsepower)
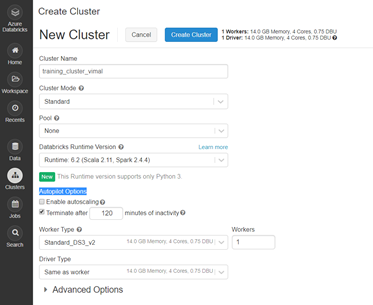
- Select “Create Cluster” to Complete. This will take a few minutes to complete.
Create and Setup a Workspace
- Open a Workspace from the left navigation menu
- Right click under the “trash” icon and select “Create-> Folder” and name it “staging”
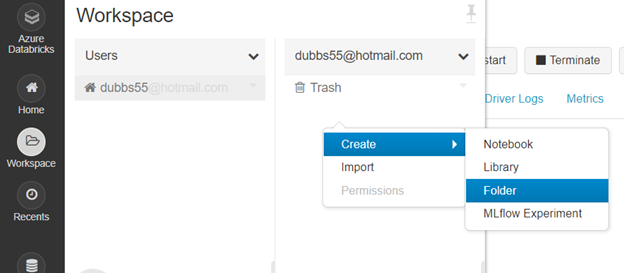
- Right click the folder and select “Create->Notebook” and name it “Data_Lake_Staging”
- Language – Python
- Cluster – “training_cluster_yourname”
- This will launch a new Workbook for your code.
Be sure to check out my full online class on the topic. A hands on walk through of a Modern Data Architecture using Microsoft Azure. For beginners and experienced business intelligence experts alike, learn the basic of navigating the Azure Portal to building an end to end solution of a modern data warehouse using popular technologies such as SQL Database, Data Lake, Data Factory, Data Bricks, Azure Synapse Data Warehouse and Power BI. Link to the class can be found here or directly here.
Part 1 – Navigating the Azure Portal
Part 2 – Resource Groups and Subscriptions
Part 3 – Creating Data Lake Storage
Part 4 – Setting up an Azure SQL Server
Part 5 – Loading Data Lake with Azure Data Factory
Part 6 – Configuring and Setting up Data Bricks
Part 7 – Staging data into Data Lake
Part 8 = Provisioning a Synapse SQL Data Warehouse
Part 9 – Loading Data into Azure Data Synapse Data Warehouse
Modern Data Architecture – Part 6 – Configuring and setting up Data Bricks