
The modern data warehouse will need to use Azure Data Lake and U-SQL to combine data. Begin by navigating to your Azure Portal and searching for the Data Lake Analytics Resource. Let’s start by creating a new Data Lake. Don’t worry, this service only charges on data in and out, not just remaining on like an HDInsights cluster so you should not be charged anything and we will not need to spin up and spin down services like we did earlier.
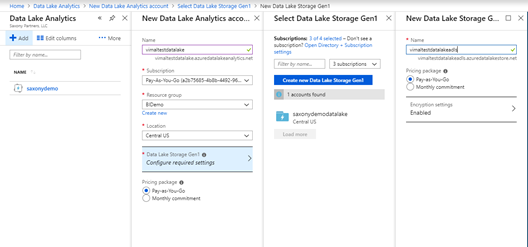
You will need to give it a unique name as well as tie it to a pay as you go subscription. A data lake will also need a data lake storage layer as well. You can keep the naming as is or rename it if you wish. It is recommended to keep the storage encrypted. Deployment may take a few minutes.
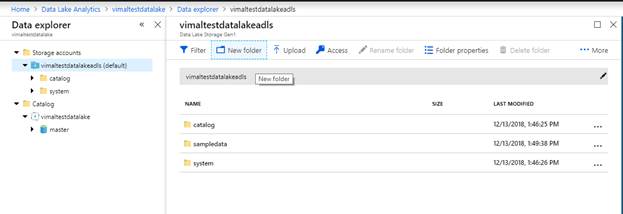
Let’s navigate to the data explore and create a new folder to put our sample data. Upload the same 3 files from the happiness index to the new folder.
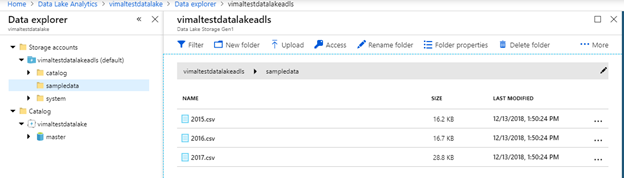
Take a look through your data explorer at the tables. It should contain a master database similar to as if you were running a traditional SQL Server.
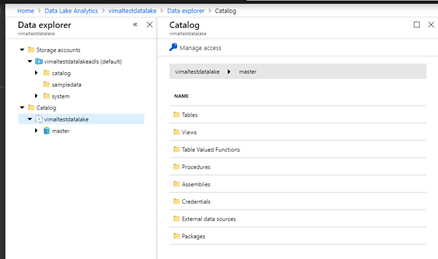
Create a new U-SQL Job that creates the new database in the catalog as well as a schema and a table.
CREATE DATABASE IF NOT EXISTS testdata;
USE DATABASE testdata;
CREATE SCHEMA IF NOT EXISTS happiness;
CREATE TABLE happiness.placeholderdata
(
Region string,
HappinessRank float,
HappinessScore float,
LowerConfidenceInterval float,
UpperConfidenceInterval float,
Economy_GDPperCapita float,
Family float,
Health_LifeExpectancy float,
FreedomTrust_GovernmentCorruption float,
GenerosityDystopiaResidual float,
INDEX clx_Region CLUSTERED(Region ASC) DISTRIBUTED BY HASH(Region)
);
While running and once completed, Azure will present the execution tree. With the new table created, we can now load data into that table.
USE DATABASE testdata;
@log =
EXTRACT Region string,
HappinessRank float,
HappinessScore float,
LowerConfidenceInterval float,
UpperConfidenceInterval float,
Economy_GDPperCapita float,
Family float,
Health_LifeExpectancy float,
FreedomTrust_GovernmentCorruption float,
GenerosityDystopiaResidual float
FROM “/sampledata/{*}.csv”
USING Extractors.Text(‘,’,silent:true);
INSERT INTO happiness.placeholderdata
SELECT * FROM @log;
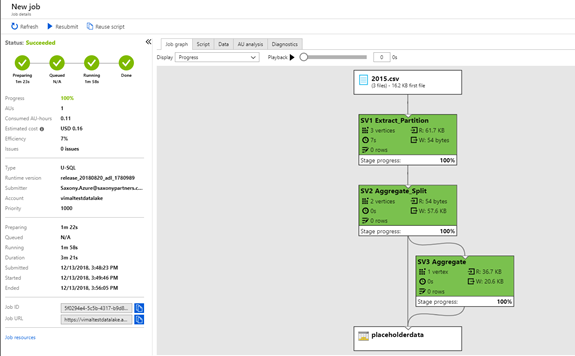
Once the data is loaded, we can go query the data in the data explorer to see what it looks like. The script will run the select and output the data to a file to be browsed.
@table = SELECT * FROM [testdata].[happiness].[placeholderdata];
OUTPUT @table
TO “/OUTPUTS/Sampledataquery.csv”
USING Outputters.Csv();
Be sure to check out my full online class on the topic. A hands on walk through of a Modern Data Architecture using Microsoft Azure. For beginners and experienced business intelligence experts alike, learn the basic of navigating the Azure Portal to building an end to end solution of a modern data warehouse using popular technologies such as SQL Database, Data Lake, Data Factory, Data Bricks, Azure Synapse Data Warehouse and Power BI. Link to the class can be found here or directly here.
Part 1 – Navigating the Azure Portal
Part 2 – Resource Groups and Subscriptions
Part 3 – Creating Data Lake Storage
Part 4 – Setting up an Azure SQL Server
Part 5 – Loading Data Lake with Azure Data Factory
Part 6 – Configuring and Setting up Data Bricks
Part 7 – Staging data into Data Lake
Part 8 = Provisioning a Synapse SQL Data Warehouse
Part 9 – Loading Data into Azure Data Synapse Data Warehouse